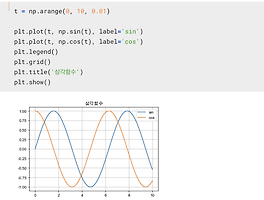
Theory/DataScience (52) 썸네일형 리스트형 웹에 있는 데이터를 가져와보자 2020. 8. 28. 19:22 데이터 사이언스 관련된 연재를 올리다가 제가 너무 바쁜 관계로 잠시 쉬었네요. 이제 다시 시작해야죠. 데이터를 다루는 것을 공부하다보면 어디서 데이터를 얻을 것인지에 대한 고민이 당연히 생깁니다. 대부분의 회사에서야 자기들만의 방법으로 데이터를 얻게 되죠. 그러나 웹에서 데이터를 얻는 방법을 알아두면 정말 재미있는 일을 많이 해볼수 있답니다.일단, jupyter notebook에서 pip install bs4를 수행해서 Beautiful Soup이라는 것을 설치합니다. 이미 설치되어 있는 분들도 있겠지만, 우리가 처음 환경을 설치하던 글에서 시작하신 분들은 설치되어 있지 않을 겁니다.그리고 세상에서 가장 간단한 사이트중 하나인 beans-r-us라는 사이트를 찾아 보겠습니다. 사실 이 사이트는 몇 개 이.. matplotlib 한글 문제 해결하기 2020. 7. 20. 08:00 이번에는 우리가 데이터 사이언스나 머신러닝을 공부하면서 많이 사용하는 Python의 그래프 그리는 툴인 matplotlib의 한글 문제를 이야기하겠습니다.일단 먼저 matplitlib와 numpy를 불러보겠습니다~그리고 간단하게 t를 0.부터 10까지 0.01간격으로 지정하고, sin과 cos을 numpy를 이용해서 그리라고 하고~, 타이틀을 "삼각함수"라고 지정했습니다그랬는데 에러가 나네요.ㅠㅠ. font에 뭔가 문제가? import matplotlib.pyplot as plt %matplotlib inline from matplotlib import font_manager, rc plt.rcParams['axes.unicode_minus'] = False f_path = "/Library/Fonts/.. Python seaborn heatmap으로 보는 서울시 구별 범죄현황 (feat. pivot) 2020. 6. 22. 08:00 이번에는 Python에서 seaborn의 heatmap을 익혀볼겸 서울시 구별 범죄현황 데이터를 다뤄보겠습니다. 이 내용은 몇 년전에 제가 지은 책(파이썬으로 데이터 주무르기)에 있는 내용입니다. 그 내용을 조금 다듬어서 오늘 이야기해보려고 합니다.~먼저 구글에서 이쁘게 검색하고~위 사이트에서 관서별 5대 범죄 발생 검거현황을 클릭~위 사이트에서 다운로드 받습니다. 다운로드를 받아서 압축을 풀고 2018년 데이터를 소스코드와 같은 폴더에 두도록 하죠~먼저 raw 데이터를 읽어봅니다. 이 데이터는 경찰서 이름, 각 경찰서마다 5대 범죄, 각 범죄마다 발생/검거가 나눠 기록되어 있습니다.~이 데이터를 정리하는 마법같은 명령어가 pivot_table입니다~~~^^ 이 명령을 위와 같이 사용하면 raw 데이터가.. 서울시 인구현황이라는 데이터 시각화해보기 2020. 5. 25. 11:00 최근 데이터사이언스 카테고리에 아주 쉬운 난이도의 글을 올리고 있습니다. 입문하시는 분들에게 작은 도움이 되었으면 좋겠다고 생각했거든요. 이번에는 서울시 인구현황이라는 통계자료가 있는데요. 그걸 한 번 다뤄보도록 하겠습니다.서울시 열린데이터에서 구할 수 있는 자료입니다. 2020년 4월 29일에 업데이트 되었네요.데이터는 휠을 조금 내리면 내려받기를 선택할 수 있습니다. 혹시 시간이 지나서 글을 읽는 분들을 위해 데이터도 같이 올려둡니다.이제 간단히 시작해보겠습니다.~그냥 한 번 읽어봤습니다. 다운로드받는 웹페이지의 안내대로 탭(\t)으로 구분해서 읽어봤습니다.그러나 대략 3번째 줄부터 읽으면 좋을것 같네요. 그래서 header는 2로 설정했습니다. 하나더, 콤마(,)들이 숫자 세자리마다 위치해 있는데요.. [Data Science] 서울시 흡연률 데이터에서 연령별 흡연률 데이터 시각화 2020. 5. 18. 08:00 이 글은 아주 쉬운 데이터를 실습용으로 사용해서 파이썬과 데이터 사이언스 분야를 공부하는 컨셉의 글입니다. 이번에 사용할 데이터는 서울시 흡연율 통계라는 데이터입니다. 해당 페이지 하단으로 이동하면저렇게 파일을 받을 수 있습니다.해당 파일은 저도 같이 공유하도록 하죠^^데이터는 매우 심플한 형태입니다.구분과 구분.1이라는 컬럼만 확인을 해보면 되겠네요이중에서 구분에 "생애주기별"이라는 데이터에 오늘은 집중하도록 하겠습니다.pandas의 DataFrame은 조건문을 이용한 데이터 선별이 아주 쉽습니다 저렇게 말이죠^^ 위 결과에서 전체, 남자, 여자만 가져오고 싶다면이렇게 하면 됩니다.이제 저장하죠. 이름을 smoke_age로 하겠습니다.이제 한글 폰트를 지정하고, (이전에도 이야기했지만, 윈도우 유저는 .. [Data Science] 서울시민들이 운동을 하지 않는 이유에 대한 분석 2020. 5. 11. 18:00 안녕하세요. 지난번에 Conda 환경을 세팅하는 이야기를 했구요. 이번에는 첫 번째 프로젝트(라고 부르기 창피하지만)로 서울시민들이 운동을 하지 않는 이유라는 통계 자료를 가지고 한 번 놀아보도록 하겠습니다. 진지하게 접근하는 것이 아니구요. 매우 간단한 파이썬 작업을 해보려고 합니다. 그러니 이 글은 파이썬을 처음 접하는 분들에게 그저 간단한 동기 부여 차원에서 진행되는 작은 글일 뿐임을 미리 이야기해둡니다.^^ 먼저 데이터를 찾아야겠죠. "서울시 운동을 하지 않는 이유 통계"라는 제목으로 구글에서 검색하면 저 글이 뜹니다. 서울 열린데이터 광장에서 구할 수 있는 데이터입니다. 혹시 데이터가 변경되어서 이 글의 코드가 동작하지 않을때를 대비해서 해당 데이터도 본문에 넣어두겠습니다. 열린데이터광장에서 저.. [Data Science] Conda 환경을 만들고 기초 모듈 설치하기 2020. 5. 10. 14:51 Python의 다양한 버전과 또 엄청~ 다양한 모듈들의 버전과 그들 사이의 관계들로 (모듈을 포함해서) 파이썬을 설치하는 경우의 수가 아주 많이 생길 수 있습니다. 어떤 때는 급하게 tensorflow 1.14 버전에서 테스트하거나, 또 어떤때는 tensorflow 2.0 버전에서 테스트해야할 수도 있지요. 이럴때 conda가 제공하는 환경을 다수 만들어서 사용하면 좋을 것 같습니다. 오늘은 그렇게 conda로 환경을 만드는 것에 대해 이야기를 하려고 합니다.일단 python 배포판에서 아마 많이들 설치하실 아나콘다를 설치해 둡니다.설치가 다 되었으면 맥 유저는 터미널을 열고, 윈도우 유저는 Anaconda Prompt를 실행하면 됩니다. 그리고 conda env list를 실행합니다. 저는 여러 환경을.. 신종 코로나 바이러스 COVID-19 데이터 분석 2020. 3. 7. 22:17 본 글은 kaggle에 공개된 신종 코로나 관련 데이터를 단순히 들여다 보는 글일 뿐, 어떤 정치적, 종교적 의도가 없습니다. 특히 데이터만 가지고 객관적으로 관찰하려 노력했으며, 글 중간에 이야기하겠지만, 글 후반부의 내용은 단지 Kaggle의 Kernel의 내용중 관심있는 부분만 정리했을 뿐입니다. 특히 Kaggle에서 가져온 데이터는 현시점 대비 정리가 다되어 있지 않아서 실시간 뉴스와 차이가 큰 경우도 있습니다. 그리고 이 글은 PC와 같은 화면 비율이 약간 큰 환경에서 읽어야합니다. 코드를 일일이 붙여넣기 힘들어서 캡쳐했기 때문입니다. 국내 아니 전세계가 신종코로나 바이러스로 인해 엄청난 긴장상태를 너무 긴 시간 유지하고 있는 것 같습니다. 예전 여러 데이터 분석관련 글처럼 이번에도 데이터를 들.. 이전 1 2 3 4 5 ··· 7 다음