얼핏 관계가 없어 보일 수도 있으나, 이번에는 scikit learn의 Label Encoder와 MinMax, Standard, Robust Scaler를 이야기 해보려고 합니다. 이 아이들 모두 데이터를 만지작 거리다 보면 자주 만나게 되는 아이들입니다.
Label Encoder
먼저 연습용 데이터를 즉석에서 만들어 보죠.

그냥 A 컬럼은 문자로, B 컬럼은 흔히 보는 숫자로 되어 있습니다.

네 위와 같이 만들어 지죠. 만약 A컬럼의 문자 a, b, c를 각각 번호 0, 1, 2를 매겨서 변환하고 싶다면 LabelEncoder를 사용하면 됩니다.
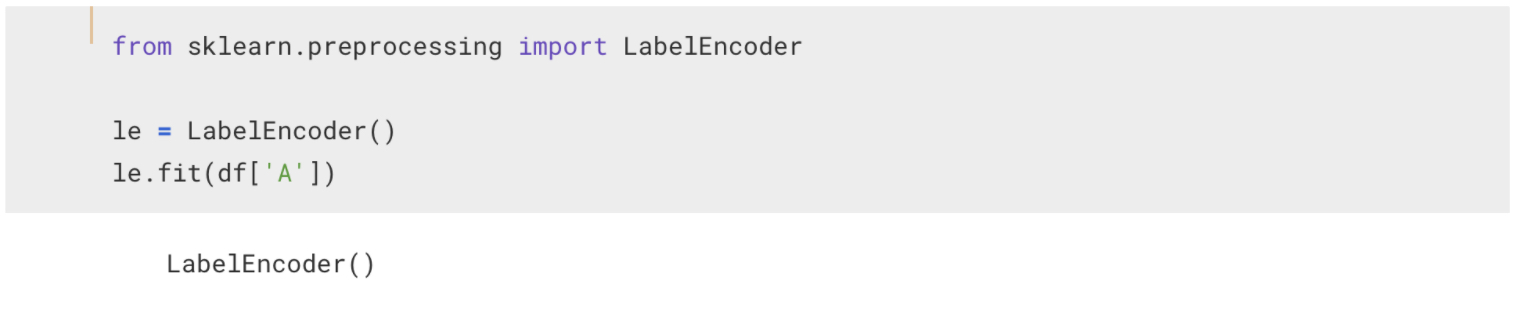
먼저 LabelEncoder를 불러와서 A컬럼을 기준으로 fit을 시키면, 어떤 아이를 0이라고 할지, 또 어떤아이를 1이라고 할지를 정합니다.

그 내용이 궁금하면 classess_를 호출하면 해당 문자가 나타나고, 그 순서대로, 0, 1, 2가 됩니다.

이제 transform 명령을 이용하면 fit에서 정해진 규칙대로 변환이 됩니다. 변환이 된것을 le_A라는 컬럼에 저장해서 보면 저렇게 되죠.

변환하고 싶으면 transform이라는 명령을 사용하면 됩니다.

방금 했던, fit과 transform을 한 번에 수행하는 fit_transform도 있습니다.

역으로 숫자를 fit한 규칙에 맞춰 원래의 문자로 변환하는 것은 inverse_transform입니다.
Min-Max Scaler
Scaler는 여러 컬럼은 일정한 범위로 옮겨놓는 것입니다. Min Max Scaler는 각 컬럼의 최대를 1로, 최소를 0으로 바꾸는 작업을 의미합니다.

x에 min값을 빼는 것이 분자에 있으므로, 분자는 x가 min일때 0을 가지게 되고, 분모에는 max - min의 값이어서 max부터 min까지의 길이가 1이된다고 생각할 수 있습니다.

위 코드처럼 df를 준비하고,

min-max scaler를 준비합니다. df를 기준으로 fit 명령까지 수행했으므로, 각 컬럼별로 max값과 min값을 찾게 됩니다.

그 결과는 위 코드처럼 저장됩니다. 각 컬럼의 최대 최소를 모두 잘 찾았습니다.
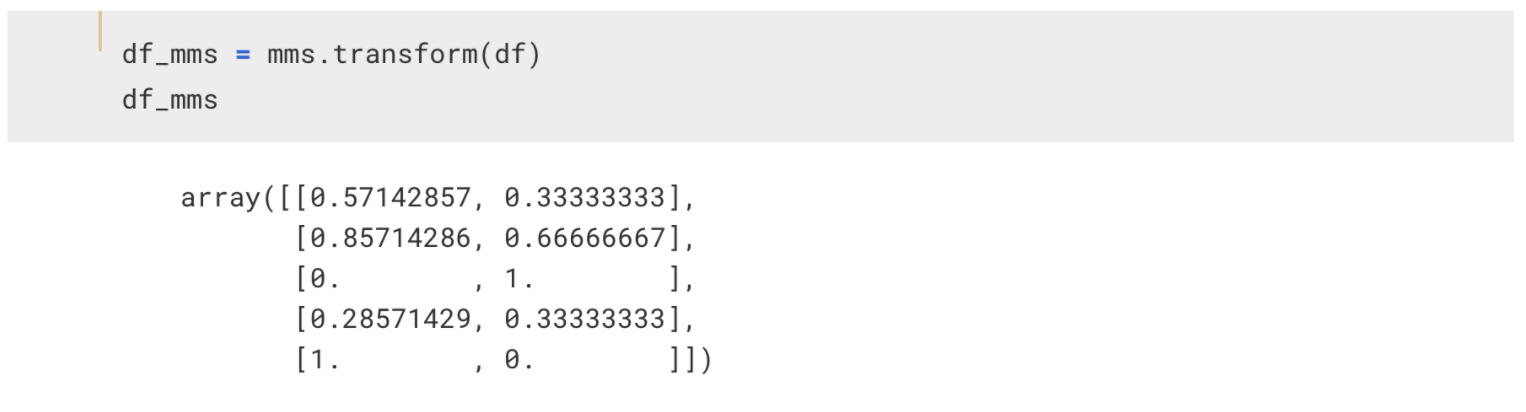
이제 df를 transform을 시키면 이런 결과를 얻을 수 있습니다.

다시 inverse_transform을 시키면 원래대로 복원되겠죠.

이 과정을 합쳐서 fit_transform을 사용할 수도 있습니다.
Standard Scaler
Standard Scaler를 표준 정규화로, 평균을 0으로 표준편차를 1로 변환하는 것입니다.
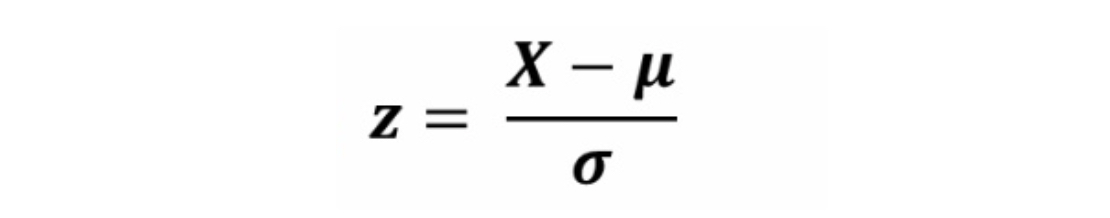
아까 min-max scaler때 만들어 둔 df를 사용하겠습니다.

Standard Scaler를 불러서, df를 기준으로 fit을 하면,

각 컬럼별로 평균과 표준편차를 계산하게 됩니다.

이를 이용해서 df를 trasform을 시키면
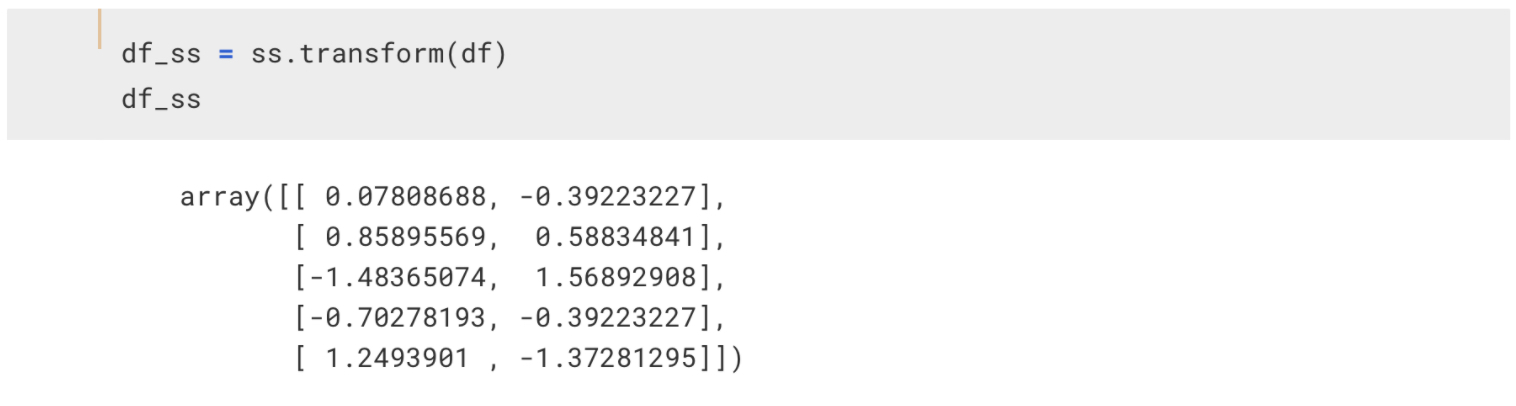
위와 같은 결과가 나타납니다.

물론 fit_transform도 가능하구요.

다시 inverse_transform을 시키면 원복되기도 합니다.
Robust Scaler
이제 Robust Scaler를 이야기하려고 하는데요. 그전에 box plot에 대해 다시 개념을 하나 확인하죠.

box 플랏에서 IQR이 데이터의 25%지점부터 75%지점을 이야기합니다. 그것을 각각 Q1, Q3라고 하고, 중간값(median)을 Q2라고 합니다.

Robust Scaler를 Q2를 0으로 잡고, Q3와 Q1의 길이 즉, IQR을 1로 변환하는 것입니다.

다시 데이터 하나를 만들고~

비교를 위해 이번에는 Min Max, Standard, Robust를 모두 불러옵니다.

각각 적용해서 컬럼을 만듭니다.

이게 그 모습이구요.

그걸 boxplot으로 그려봅니다.
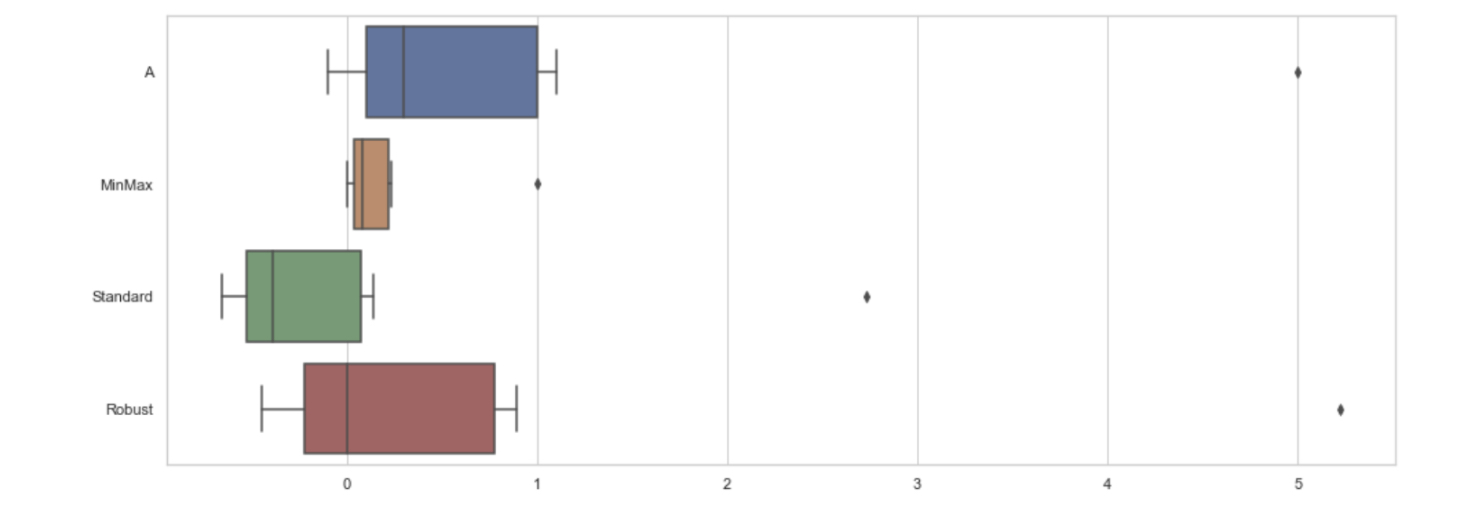
원 데이터 A에 대해 MinMax와 Standard, Robust 모두 특성이 잘 보입니다.
'Theory > DataScience' 카테고리의 다른 글
| 소리나 음원, 음악 데이터에서 주파수 특성 분석 - librosa (8) | 2022.02.24 |
|---|---|
| Selenium 처음 시작해 보기 (11) | 2021.09.30 |
| Jupyter Notebook을 원격으로 접속하기 (8) | 2021.04.08 |
| Box Plot의 기초 (6) | 2021.03.24 |
| Colab에서 KoNLPy와 WordCloud 설정하기 (4) | 2021.01.15 |
| 한글 형태소 분석기 KoNLPy 사용을 위한 환경 설정 해보기 (8) | 2020.12.23 |
| 네이버 검색 결과를 API를 이용해서 쉽게 받아보자 (6) | 2020.10.13 |



